
本文整理自 OSCS 软件供应链安全技术论坛- 边立忠(京蛰)老师的分享《蚂蚁供应链安全建设实践》完整内容。
边立忠,蚂蚁集团高级安全专家,蚂蚁集团应用安全产品中台负责人,主要负责蚂蚁 SCA、IAST、SAST、镜像安全扫描等供应链安全相关产品的建设和技术研究。
大家好,我是边立忠,很高兴今天有机会给大家做一个软件供应链安全相关的分享。
我在蚂蚁主要负责 DevSecOps 的工具链,或者叫工具矩阵的建设,以及供应链相关的产品建设。所以今天带来的软件供应链安全建设除了囊括我团队负责的这一部分以外,还会囊括蚂蚁其他在供应链相关的建设的内容。今天我作为代表,整体来给大家做这样一个分享和介绍。
将从以下几个部分来进行分享:
- 蚂蚁供应链安全概述:风险、挑战、建设思路;
- 风险检测;
- 安全管控;
- 纵深防御;
- Log4j经典案例:如何被应急响应、处置和管控风险
蚂蚁供应链安全概述
软件供应链安全范畴
蚂蚁从供应链相关的风险来区分供应链安全,对我们实际的业务造成了安全影响,就把它定为一个供应链安全相关的范畴。
蚂蚁当前最大供应链风险:代码的直接或间接依赖、三方软件。
直接依赖会直接影响业务可信,其中包括:
- 源代码
- 代码的直接依赖
- 运行时系统软件
- 容器镜像及OS
- 底层硬件设备
间接依赖间接影响业务可信,其中包括:
- 研发工具、平台
- 代码的间接依赖
- 制品下载分发平台
- 人、角色
- 制品更新平台
次间接依赖存在更多的攻击渠道,其中包括:
- 人所处物理环境
- 人使用的设备
- 人所在网络环境
- 间接依赖的上下游
- ……
随着蚂蚁整个应用的量级、业务的量级不断增长、不断膨胀,直接依赖同样有着非常大的增长。在直接依赖本身增长的前提下,间接依赖和次间接依赖就会呈几何量级出现爆发式增长。这种爆发式增长的上下游依赖,给我们带来了难以穷举的防护目标。
但是从历史的 case 来看,其实蚂蚁供应链最大的风险一方面是来自应用的直接依赖和间接依赖,另一部分是来自于三方软件。所以说今天我的分享是会围绕这个范畴来给大家展开。
软件供应链风险态势
第一,软件的下载量逐年呈现快速增长。软件本身在增长的前提下,软件的量级增长,就会引入错综复杂的应用的供应链关系。
另一个是供应链的攻击事件。供应链的安全事件也在逐年呈指数级增长。并且它的攻击手法更加的隐蔽,影响范围也更加广泛。
以下列出了从 15 年到 21 年的比较严重或者说大家认知、感受比较明显的供应链的事件。对于蚂蚁来说,从安全的维度供应链的风险分为两类,一类是漏洞,另一类是供应链的投毒。那后面也是会围绕这两个方向给大家展开来做介绍。

蚂蚁供应链安全防护体系
对于应对漏洞以及投毒的风险,蚂蚁是如何进行防护的 。
整个供应链安全防护体系主要分为三个部分(三位一体的防护体系),包括风险监测(发现风险)、安全管控(控制风险)以及纵深防御(化解风险),每一部分需要的一些工具能力如下图。
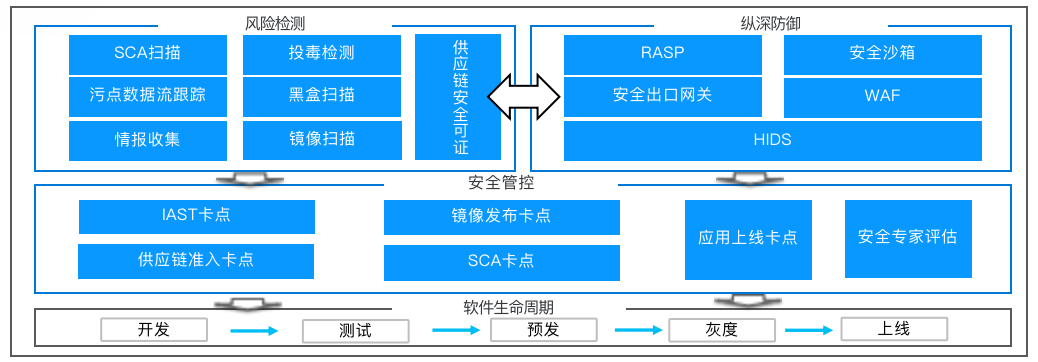
就像是当下的疫情防控的几个阶段,核酸检测-风险管控-疫情治疗。
风险检测-发现风险
- 情报监控/收集
- 潜在供应链漏洞挖掘
- 供应链投毒检测
- 影响面快速排查
安全管控-控制风险
- 供应链组件准入
- 供应链组件引用准入
市面上的开源供应链到底有哪些风险、哪些有风险,哪些没风险,我哪些应该管控。所以中间总会存在一些漏网之鱼,或者说总会存在预期之外的情况。但是对于蚂蚁金融属性非常强的公司来说,这样的风险遗漏是无法承受的。我们就提出了纵深防御的概念,我们需要通过纵深防御的理念,在真正发生风险的时候,供应链的组件实际触发风险的时候,能够来对风险进行管控。
纵深防御-化解风险
- 攻击检测
- 攻击阻断
- 风险隔离
三位一体的防御体系,最终达到的目的是风险的发现,控制风险以及风险的化解。
风险检测
供应链安全检测产品矩阵
这是我们供应链安全检测的整个的产品矩阵,可以分成上中下三部分来理解。

首先上面是各个业务,同时这些供应链的产品为了服务业务线,我们实现了独立部署平台化,包括多租户的 SaaS 化模式。
另一个当供应链风险发生的时候,需要检测的范围是什么?所以说我们会有自己的资产平台,围绕我们保护的资产到底要什么?举个例子:首先我们知道 URL 和域名是什么、 URL 和域名对应的 IP 是什么、 VIP 对应的主机是什么、主机开的端口是什么、端口所对应的进程是什么、进程上跑的应用是什么?应用哪些、接口包括应用的代码库是什么、数据是不是敏感数据、能够访问到的数据用到的数据是什么?基于这样的资产的透视,我们就可以知道要保护的目标是什么。
基于我们保护的目标,就会去构建整体的供应链的检测产品。供应链检测的产品也可以分为上下两个部分来解读。下面这部分更多是说我们实际发现哪些组件存在供应链的风险。这中间就包含了我们要做情报的收集,情报的监控,包括自研的收集渠道,外采的渠道,以及墨菲合作的情报收集、监控。并且情报是需要有研判的,因为很多 cve 的漏洞,这些情报好多都是实际没有什么风险的,没有实际攻击的链路,但是它也会被作为一个情报公开出来。所以说情报首先是需要做研判的,另外也会对公开的情报、非公开情、潜在非公开漏洞或潜在漏洞的进行研究。
这里就涉及到了工业软件的可证,基于我们污点建模的能力,构建出了静态和动态的跟踪能力,包括重打包的能力。前面的老师也有讲到说,那我这有一个包,比如说我有 Fastjson 这个包,我拿过来内部改一改,直接把代码引入到我的项目里面去。那这其实也是一个供应链的问题,我们也会有这样代码相似度的检测,在里头去发现重打包的一些问题。
另一个我们会有一些投毒检测,它包含了通过底层的操作系统切面,包括一些应用的切面,在实际的运行过程当中去感知它有没有投毒的行为。这中间就包含安装的检测、 query 的检测,以及函数实际调用过程当中 fuzz 的检测。那么基于这个能力,上半年总共检测出来 1000 多个存在投毒的 node 的组件。
再回到上面部分,这部分更多是实际知道了哪些供应链的组件存在安全风险之后,如何去做影响面排查的能力,或者说如何去做增量检测的能力。上面分为左半部分和右半部分。左边更多是业务在上线前用到的检测产品。比如说白盒代码扫描,我们会在白盒代码扫描里面会集成 SCA 的扫描能力,包括特征扫描能力、污点追踪扫描能力。我们会去看比如说某个组件存在了 CVE 漏洞,那它在实际业务使用过程当中,它的整个攻击的链路能不能触达,或者说实际的攻击的参数能不能被外部可控,那当然我们也会有一些代码画像的能力。
下面是我们目前支持的一些语言,其实我们也在研究建统一的语法书,因为现在业界的各种白盒扫描的产品,各个语言之间的建设,比如说 Java 的 node 的语言都会去自建一套,比如每个语言都会去做一套 IAST 的这种解析,那我们希望说的 IAST 能够有一个统一的表达,然后在这基础上建一个统一的污点追踪引擎。所以说我们会建立统一的语法树做支撑。
另一个就是交互式扫描,交互式扫描会有基于动态的跟踪,包括动态的污点追踪,代码的画像之类等。然后也会支持更多的语言。
另一个部分,业务经过了开发测试到达打包的时候,打包完镜像的时候也有扫描。镜像扫描主要做比如供应链 RPM 的扫描、供应链的 jar 包,供应链组件的扫描以及敏感信息的扫描,包括恶意程序木马扫描。之后应用就发布上线,到线上之后,我们会有线上的一些能力和产品来自动化的去发现安全风险。主要就包括了应用的安全的透视。
这是我们整体的检测机制,检测的产品矩阵。然后我们也在做另外一个事情:软件供应链的可证。
软件供应链可证
我们现在其实在尝试做可证,可证跟检测有什么不同呢?可证其实我们其实为了区分三种情况:
- 安全的,存在漏洞或投毒行
- 不安全的,存在漏洞或投毒
- 暂时无法判断,存疑的
其中一种是暂时我们判断不了的,通过我们工具、机器不能判断,那么它是存疑的。这个时候我们就可以推荐用户去用我们认为安全的。假如说同样功能做 JSON 解析、做 XML 解析,我们可以推荐用户去用我们认为安全的,或者说我们认为经过可证的分析认为这个组件不太可能在未来会被曝出这种供应链漏洞。那么暂时无法判断的,可能通过人工运营去判断。通过人工+工具的这套体系,也能够帮助我们漏洞研究的同学去挖掘一些潜在的 0 day 或潜在的安全的漏洞。
软件供应链可证的功能或工具是结合了我们本身在 IAST 和 SAST 这一块积累的动态和静态分析的经验所构建出来的。第一,我们可以拿到它的代码特征,并且可以拿到它的动态和静态的风险的调用链路。基于这些风险调用链路、依赖关系,可以去做代码画像,比如说链路的画像、依赖的画像。然后看组件它到底有没有高风险的行为,并且说高风险的行为是不是存在可控的情况。最终我们可以推断出来可证的这三个维度的数据。
可证是今年才开始做的,目前来看,我们结合人工+工具已经发现已发现google、apache等多个基础组件的安全0day。(已报备给相关单位)
安全管控
这部分是我们软件供应链安全管控的整体的流程。
其中安全管控分为两个部分,一部分是组件进入到内部的,蚂蚁有个内部的制品库,包括 Python 、 Npm 、Java 的都有内部的制品库,所以在外部的组件用户上传,还是中央仓库同步,都会经过投毒检测、 DAST 检测,最后入到内部制品库。
录入到内部制品库之后,接下来就是实际生产资料被实际使用的过程,当中我们也有准入的管控。使用过程分为两个场景,目前关注比较多的是第一个场景,我在使用过程当中被我实际的应用使用了。另一个场景可能关注比较少,就是计算任务这种场景。但是在蚂蚁有大量这种计算,大量这种场景,比如说 UDF 的计算任务跑在大数据平台上,那这个计算任务它也会存在供应链的问题,无非就是计算任务的一个插件,包括比如说那种压测的平台,它也可以写压测插件,这种也是会存在供应链的风险的。并且之前我们也检测到这种风险被触发的这种情况。这块我们来做一个简单的介绍。
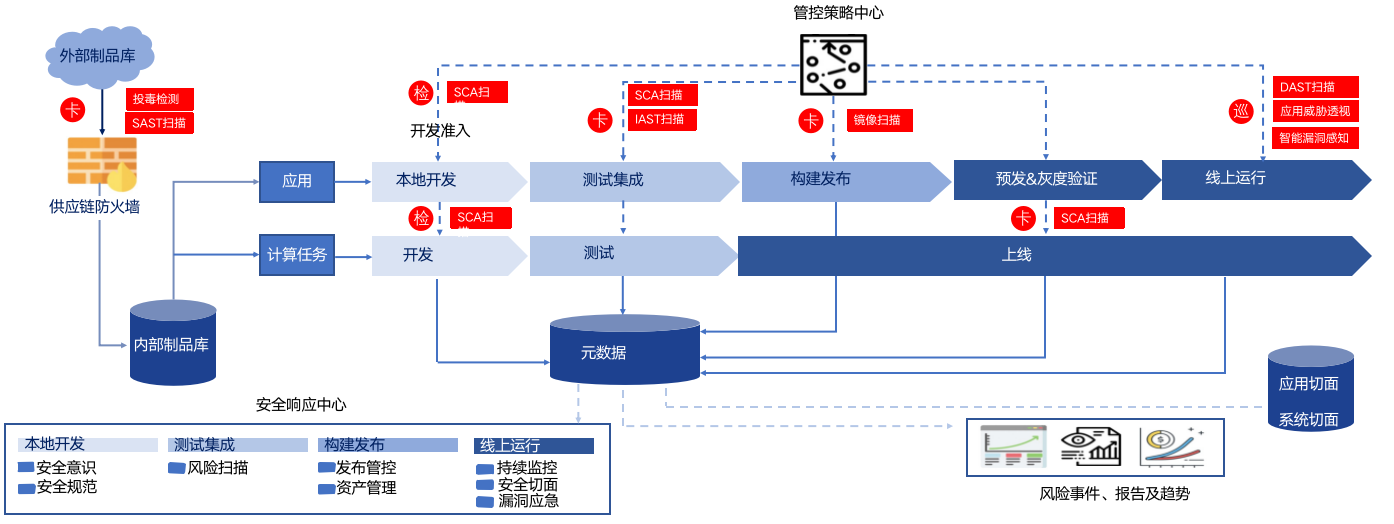
首先在开发阶段,我们会有开发准入,会有 SCA 的扫描,会提醒开发说你有什么样的风险,需要去把这些风险修复掉。集成测试的时候会 SDK 扫描,包括 IAST 的检测。这个时候我们会形成一个卡口的机制,因为集成测试的时候代码基本就是一个稳定态了。那接着到构建发布的时候,镜像构建完了,我们也会有构建发布阶段的镜像扫描,这个时候也会对供应链问题进行卡口。
然后真正线上运行的时候,我们会去做 DAST ,包括应用威胁透视,智能漏洞感知,例行的巡检扫描。计算任务也是一样的,从开发测试到上线,由开发阶段有检查,上线阶段有卡点。所有的数据最终会汇集到元数据中心,元数据中心结合风险报告以及风险事件,再回流到应急响应中心,就能够快速地来应对。比如说新出现的这种 CVE 的漏洞,投毒事件,我们能快速地知道它的影响面。
纵深防御
供应链问题其实是一个混沌的问题,混沌的问题我们通过检测和管控并不一定能百分百的把这些风险都解决掉。这个时候就需要我们去考虑实际风险发生的时候,怎么来控制风险和隔离风险,或者说消除风险。那我们就提出了纵深防御的思想,好多人可能玩过塔防的游戏,我结合塔防的游戏来给大家讲一下什么是纵深防御。

第一,玩塔防的时候不会把防御塔建在一起,就建在一个节点,因为建在一个节点的情况下,这些小兵通过了这个节点后面就畅通无阻了。所以说关键的节点必然是层层设卡的。
第二,各个防御塔之间的功效肯定是互补的。有些防御塔是直接给对小兵造成伤害的,有些防御塔是给小兵造成眩晕的,让它跑得慢一点,能让攻击的时间长一点。所以说防御的能力之间肯定是互补的。
第三,塔防游戏本身在设计上是不允许有捷径的。所谓捷径就是中间有草坪或者高的障碍物,小兵是没法直接通过障碍物到达终点的。其中很重要的一点就是我们要杜绝攻击捷径,也就是所谓的隔离。这就是我们纵深防御的思想。
总结,关键节点,要层层设卡;防御能力互为补充;杜绝攻击的捷径。
网络层面纵深防御
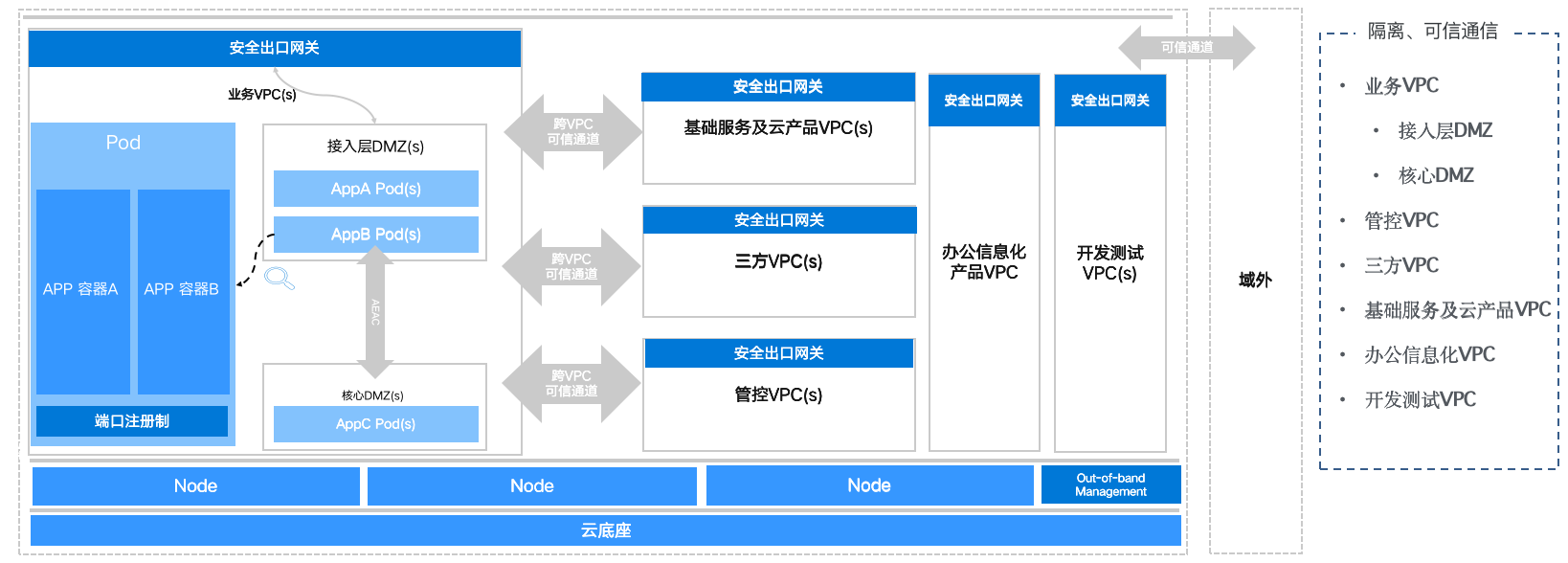
网络层面纵深防御更多强调的是隔离和可信通性。蚂蚁会对网络、应用进行分类分级。比如下面是云底座,上面是各个 Node ,再在上面是一些 VPC 。比如有三方的 VPC ,还包括一些重要的管控风险比较大的,就会放在管控 VPC 里面,包括办公信息化产品的 VPC 、测试开发的 VPC ,都是互相隔离的,它们之间的通信只能通过跨域 VPC 的可信通道才能通信。这是网络层面 VPC 层面的隔离,另一个就是隔离之后的可信通信。
在具体的 VPC 内,我们会去做具体 VPC 内更细粒度的隔离。比如一个 VPC 内各个应用,它的属性是不一样的。比如说业务 VPC 它有核心的一些应用,我们会通过 DMZ 的这种方式,把它隔离在一个核心的 DMZ 里面去,一些揭露层的、直接对公网暴露的,会到揭露层的 DMZ 这里面去。这个好处是什么? 在某一个区域爆发的供应链安全风险,它只能在有限的范围内进行扩散,它要扩散到别的 VPC 其实成本是很高的。
计算纵深防御
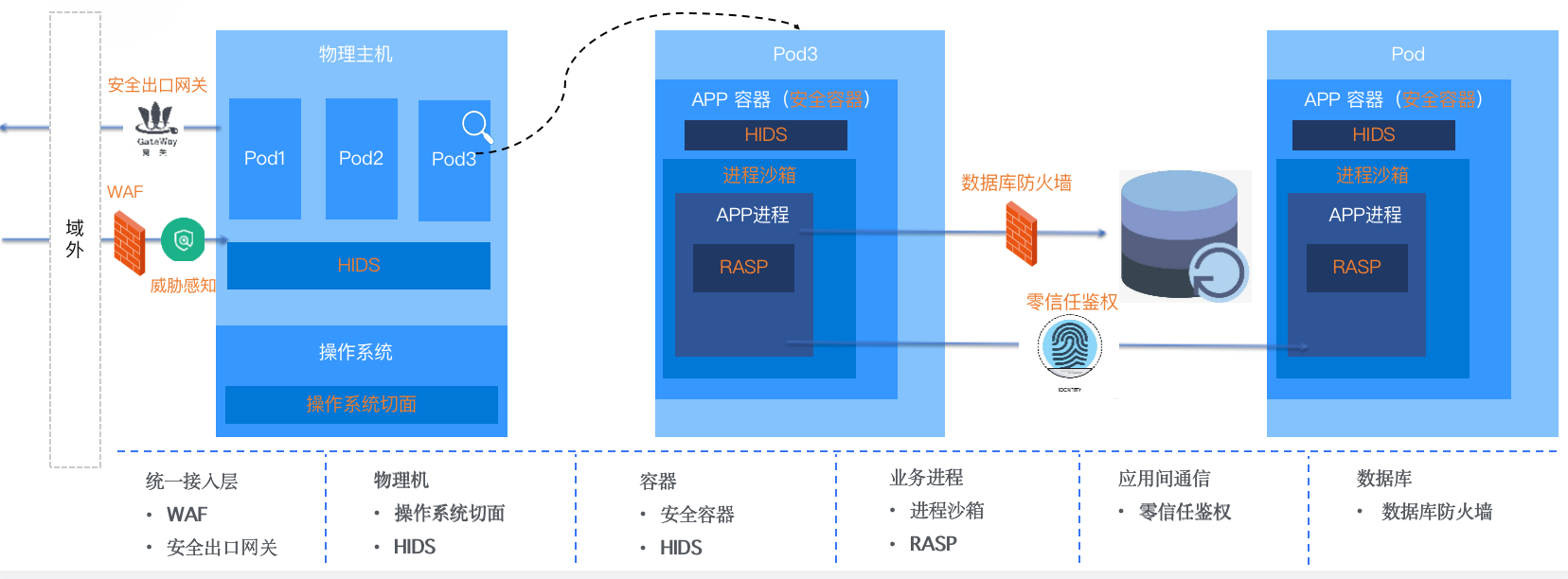
具体的某个 VPC 内,是怎么来建设纵深防御这套机制的,把它称之为是计算纵深防御。
主要是两类风险,一类是漏洞,另一类是投毒的攻击。计算纵深的防御是从安全的网关、流量的接入层、物理主机、容器进程这些维度的一个防御。
切面在纵深防御中的应用
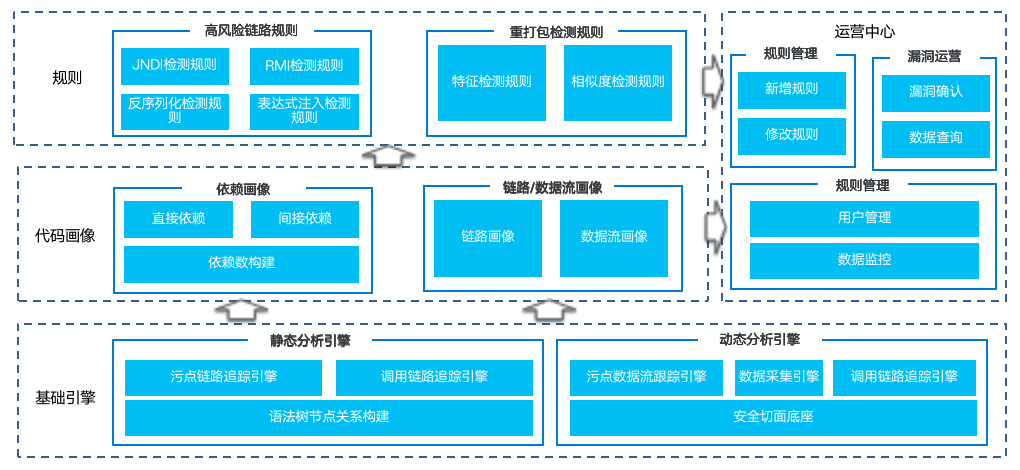
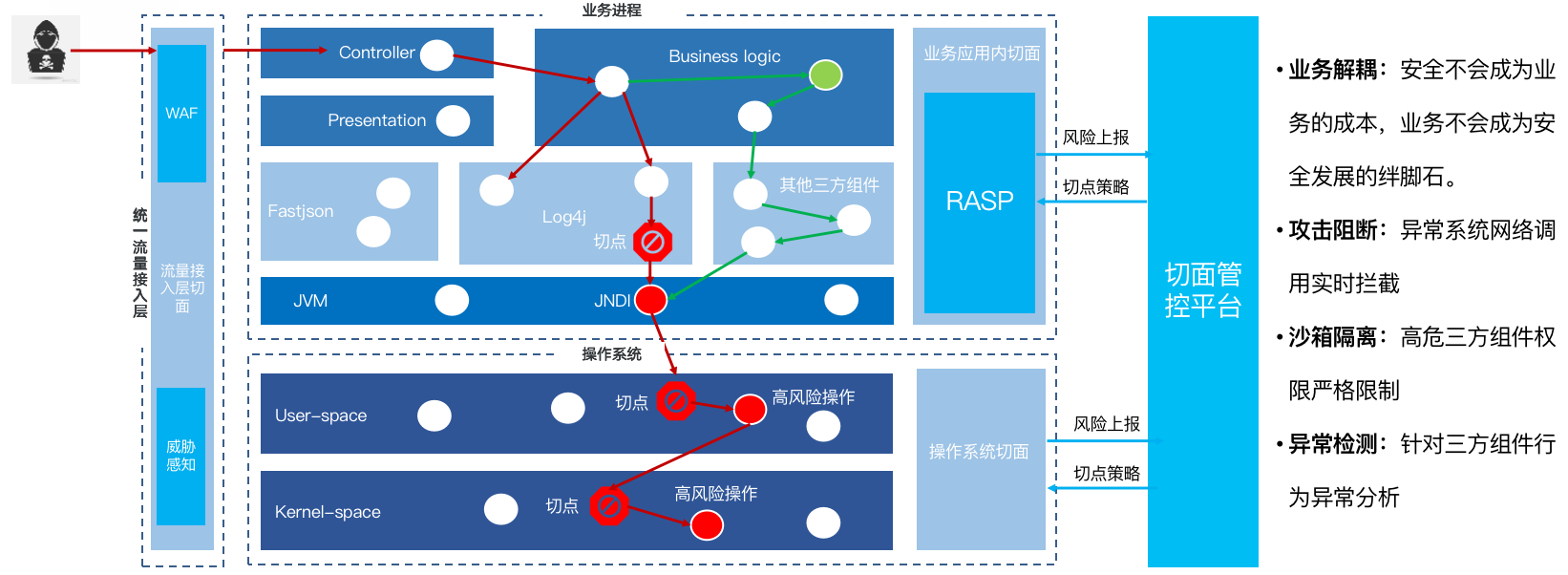
纵深防御的整个体系里面很关键的一点是切面,在多个环节都得到了很好的应用。
在纵深防御里面的应用,首先统一接入层,会有一个切面,攻击者的流量进来之后,会在流量的统一接入层有 WAF 、有智能感知,通过流量的方式拦截风险。当真正的请求到达 controller 、业务逻辑的时候,本身我们的 RASP 基于切面的底座或切面的技术,我们会有关键的切点。所以说当有一个有风险log4j 触发 JNDI 的这种行为的时候,就会被切点监控到,并且会被这个切点拦截。所以说基于切面能力应用在纵深防御里面的时候,能够做到攻击阻断、沙箱隔离、异常检测的能力。但是最重要的一点是通过切面的理念被应用到了整个综合防御里头。
我们会发现安全不会再成为业务的一个成本,安全和业务本身是解耦的,其实安全的一些方案难推动,更多是安全会成为业务的成本,要落地方案,业务必须配合我去做一些改造或帮助安全去承担这样的成本。但切面很好,因为它本身是和业务平行的,这种情况下安全就不会成为业务的一个成本。并且安全是真正助力业务去做、去成功的一个能力。
小结
1、关键节点(攻击者必经之路)层层设卡
- 统一接入层
- 物理机
- 容器
- 业务进程
- 应用间通信
- 数据库
2、各防御能力互为补充
- 流量视角
- 应用内运行时视角
- 操作系统视角
- 应用间视角
3、杜绝攻击捷径(隔离)
- VPC隔离
- vDMZ隔离
- 进程沙箱
- 安全容器
Log4j 典型案例
最后来分享一下 Log4j 的典型案例,在蚂蚁是怎么被应急处置以及到变成日常的例行管控的。
首先分为两条线:上面那条线主要介绍的是漏洞止血,下面一条线是影响面排查和漏洞修复,这两条线在实际应急过程当中是并行的,两条线同时触发同时往前推进的两条线。
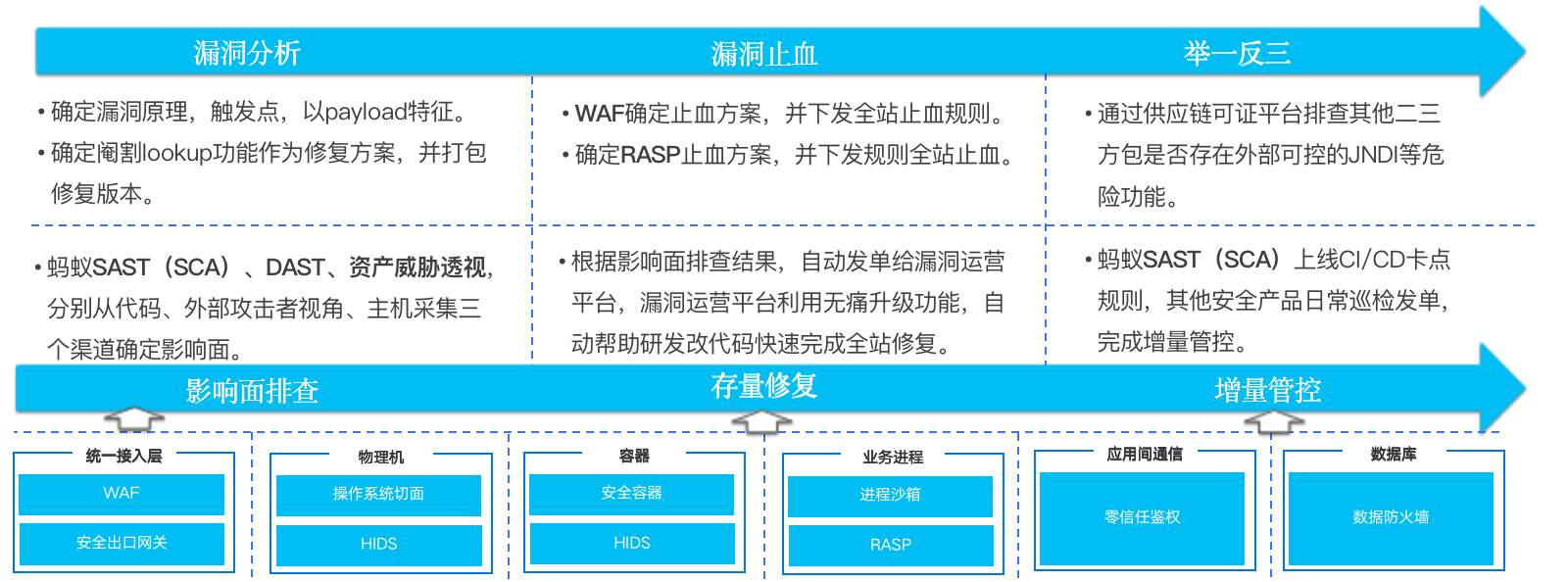
整个漏洞的应急本身肯定是从漏洞分析开始的,所以第一步是确定漏洞的原理、触发点、payload 特征。这个时候很重要的一点是修复方案是什么?我们是要有一个决策的。
漏洞分析 – 漏洞止血 – 举一反三
因为我们收到情报的时候,官方还没有给出修复版本,并且官方给的修复版本,可能只会修一个最高版本,而修一个最高版本的情况下,蚂蚁是没法落地的,蚂蚁的实际使用的版本是非常分散的,没有做版本的收敛,所以说真的要升级的时候,兼容性是一个很大的问题。
另一个问题是我们不知道官方什么时候会出新版本,这段时间的风险敞口怎么办?
基于以上两个点,我们做了一个决策,确定阉割 lookup 的功能作为修复方案,并且我们自己去打包一些小版本来帮助业务快速的修复。
做完漏洞分析之后,知道了漏洞的一些特征,接下来全站下发WAF 的止血方案,进行全栈的止血;并且也知道了RASP漏洞触发的原理,确定 RASP 的止血方案,并且全栈下发方案,止血到节点,全栈的止血已经完成了。
后续我们要举一反三地去排查是不是还有二三方组件存在同样的 JNDI 可能被攻击的供应链安全风险,以上这是漏洞止血这一条线。
影响面排查-存量修复-增量管控
另外一条线同步进行的是影响面排查和存量修复这条线,这条线主要是依赖上面的漏洞分析的结论。
蚂蚁的 SAST(SCA)、DAST、资产威胁透视,分别从代码、外部攻击者视角、主机采集三个渠道确定完整的影响面。确定影响面后,接下来就推修了,根据实际排查的影射层面,自动发单给漏洞运营平台,漏洞运营平台利用无痛升级功能,就能够很简单地自动帮助研发改代码,快速完成全站修复。大大地加快了业务去理解漏洞并且修复漏洞的成本。
当整个修复进展到一定程度的时候,就需要去考虑怎样管控增量。蚂蚁在 CI|CD 的流程上配置了卡点规则,在上线前就进行一些安全的卡控。还有其他安全产品也会进行线上的增量巡检发单,完成增量管控。
在这里我举了一个比较有代表意义的,下方比如 HIDS这类安全容器 、RASP 等在整个过程中也发挥了非常重要的作用。
